Language-Conditioned
Among all the baseline methods, Diff-Control achieves the highest success rate with 92%, which is 5%, 64%, and 32% higher than diffusion policy, ModAttn, and Image-BC, respectively.
While imitation learning provides a simple and effective framework for policy learning, acquiring consistent action during robot execution remains a challenging task. Existing approaches primarily focus on either modifying the action representation at data curation stage or altering the model itself, both of which do not fully address the scalability of consistent action generation. To overcome this limitation, we introduce the Diff-Control policy, which utilizes a diffusion-based model to learn action representation from a state-space modeling viewpoint. We demonstrate that diffusion-based policies can acquire statefulness through a Bayesian formulation facilitated by ControlNet, leading to improved robustness and success rates. Our experimental results demonstrate the significance of incorporating action statefulness in policy learning, where Diff-Control shows improved performance across various tasks. Specifically, Diff-Control achieves an average success rate of 72% and 84% on stateful and dynamic tasks, respectively. Notably, Diff-Control also shows consistent performance in the presence of perturbations, outperforming other state-of-the-art methods that falter under similar conditions.
Among all the baseline methods, Diff-Control achieves the highest success rate with 92%, which is 5%, 64%, and 32% higher than diffusion policy, ModAttn, and Image-BC, respectively.
Diff-Control policy is able to achieve this high-precision task with 80% success rate over 25 trials, Diff-Control policy demonstrated superior performance and does not show the tendency to overfit on idle actions.
Diff-Control policy achieves a commendable success rate of 84% while performing in this dynamic task. It demonstrates a tendency to scoop the duck out in a single attempt, reaching a low enough position for accurate scooping.
Diff-Control achieves the highest success rate of 72%, it is able to predict the direction of actions correctly (upward or downward) and knows when to halt the actions. The stateful behavior is beneficial for robot learning periodic motions.
The key objective of Diff-Control is to learn how to incorporate state information into the decision-making process of diffusion policies. In computer vision, ControlNet is used within stable diffusion models to enable additional control inputs or extra conditions when generating images or video sequences. Our method extends the basic principle of ControlNet from image generation to action generation, and use it as a state-space model in which the internal state of the system affects the output of the policy in conjunction with observations (camera input) and human language instructions.
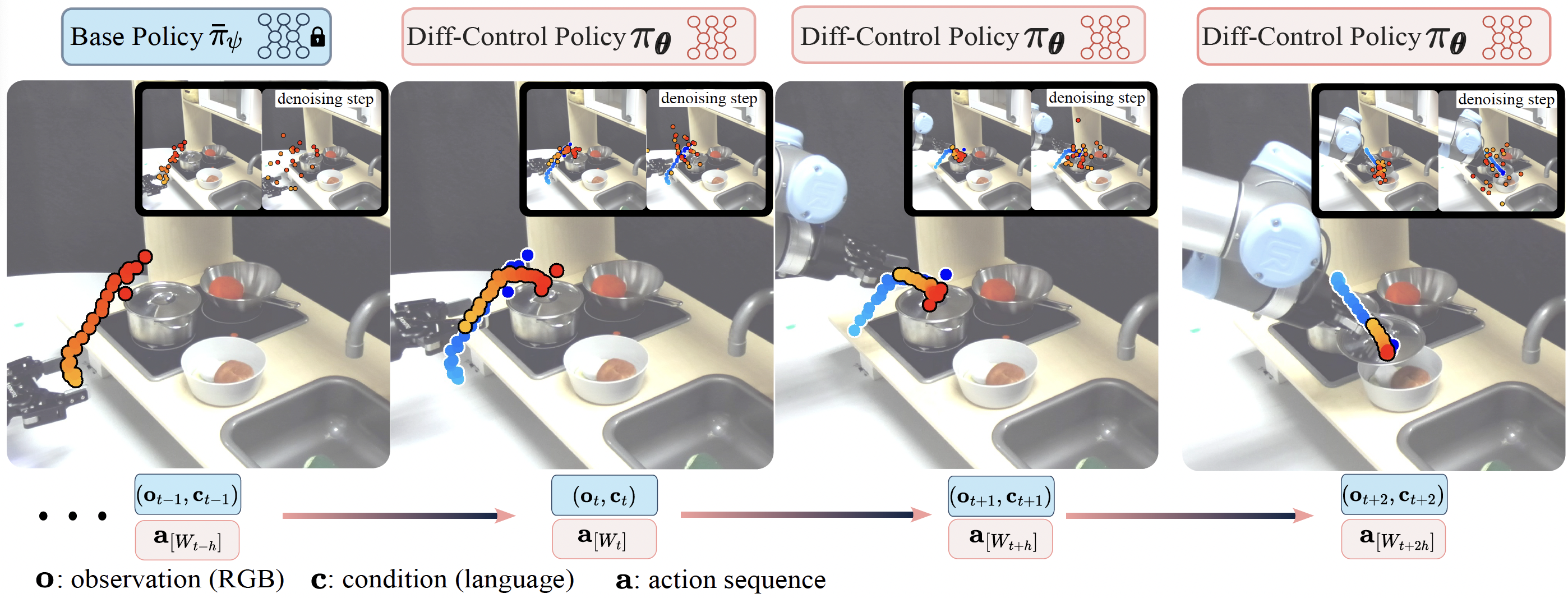
Diff-Control operates by generating a sequence of actions while incorporating conditioning on previously generated actions. In this example, the Diff-Control policy is depicted executing the "Open Lid" task. For instance, in the second sub-figure, the blue trajectory represents previous action trajectory, denoted as a[Wt], while the red trajectory displays the newly generated sequence of actions, denoted as a[Wt-h].
We find that proposed Diff-Control policy effectively maintains stateful behavior by conditioning its actions on prior actions, resulting in consistent action generation. An illustrative example for this behavior is shown below: a policy learning to approximate a cosine function. Given single observation at time t, stateless policies encounter difficulties in producing accurate generating the continuation of trajectories. Due to ambiguities, diffusion policy tends to learn multiple modes. By contrast, Diff-Control integrates temporal conditioning allowing it to generate trajectories by considering past states. To this end, the proposed approach leverages recent ControlNet architectures to ensure temporal consistency in robot action generation.
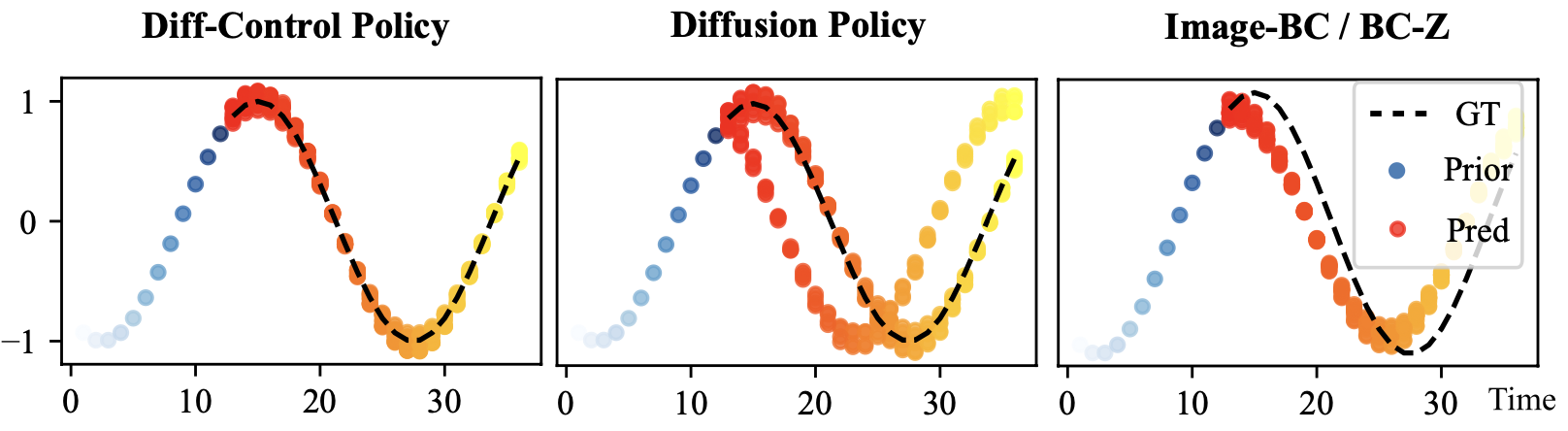
At a given state, Diff-Control policy can utilize prior trajectories to approximate the desired function. Diffusion policy learns both modes but fails on generating the correct trajectory cosistently, Image-BC/BC-Z fails to generate the correct trajectory.

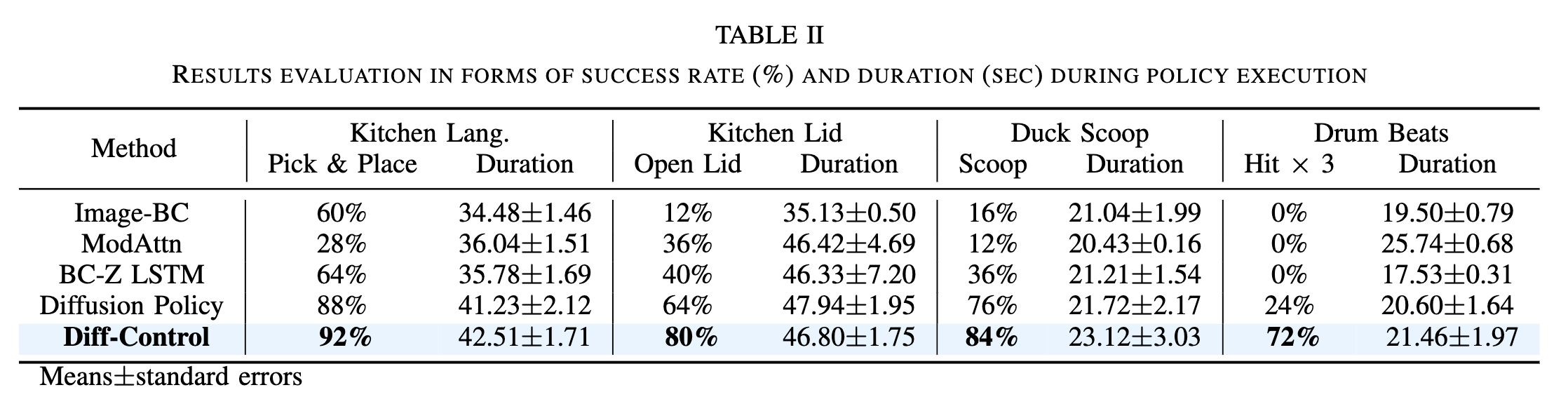
To assess the performance and effectiveness of our approach, we conducted comparative evaluations against robot learning policy baselines.
Diffusion Policy serves as the base policy in proposed framework, similar design decisions has been made referring to the visual encodings, hyper-parameters, etc.
We adapt ControlNet sturcture, expecially the zero convolusion layers to create Diff-Control in robot trajectory domain.
Besides diffusion policy, we compared Image-BC/BC-Z baseline, the ModAttn baseline, and BC-Z LSTM.
@article{liudiff,
title={Diff-Control: A Stateful Diffusion-based Policy for Imitation Learning},
author={Liu, Xiao and Zhou, Yifan and Weigend, Fabian and Sonawani, Shubham and Ikemoto, Shuhei and Amor, Heni Ben}
}@article{liu2024enabling,
title={Enabling Stateful Behaviors for Diffusion-based Policy Learning},
author={Liu, Xiao and Weigend, Fabian and Zhou, Yifan and Amor, Heni Ben},
journal={arXiv preprint arXiv:2404.12539},
year={2024}
}